Transfer Learning for Prosthetics Using Imitation Learning
This project tries to apply Reinforcement Learning (RL) to enable prosthetics to calibrate with differences between humans and differences between walking environments using OpenSim simulator to mimic the prosthetic motions and apperance.The project is a part from NeurIPS 2018: AI for Prosthetics Challenge

Codes
Publications and Awards
-
Best Graduation project at University of khartoum. 2018. Khartoum, Sudan
-
Poster paper at NeurIPS 2018 Black in AI workshop, Montreal, Canada
- Poster at Deep Learning Indaba 2018, South Africa
Objectives
-
Benchmarking RL algorithms: Deterministic Policy Gradient DDPG, Trust Region Policy Optimization TRPO and Proximal Policy Optimization PPO algorithms.
-
Reduce training time using Imitation Learning algorithm Dataset Aggregation algorithm DAgger.
- Modificat DAgger algorithm to balance between exploration and exploiting.
OpenSim Enviroment
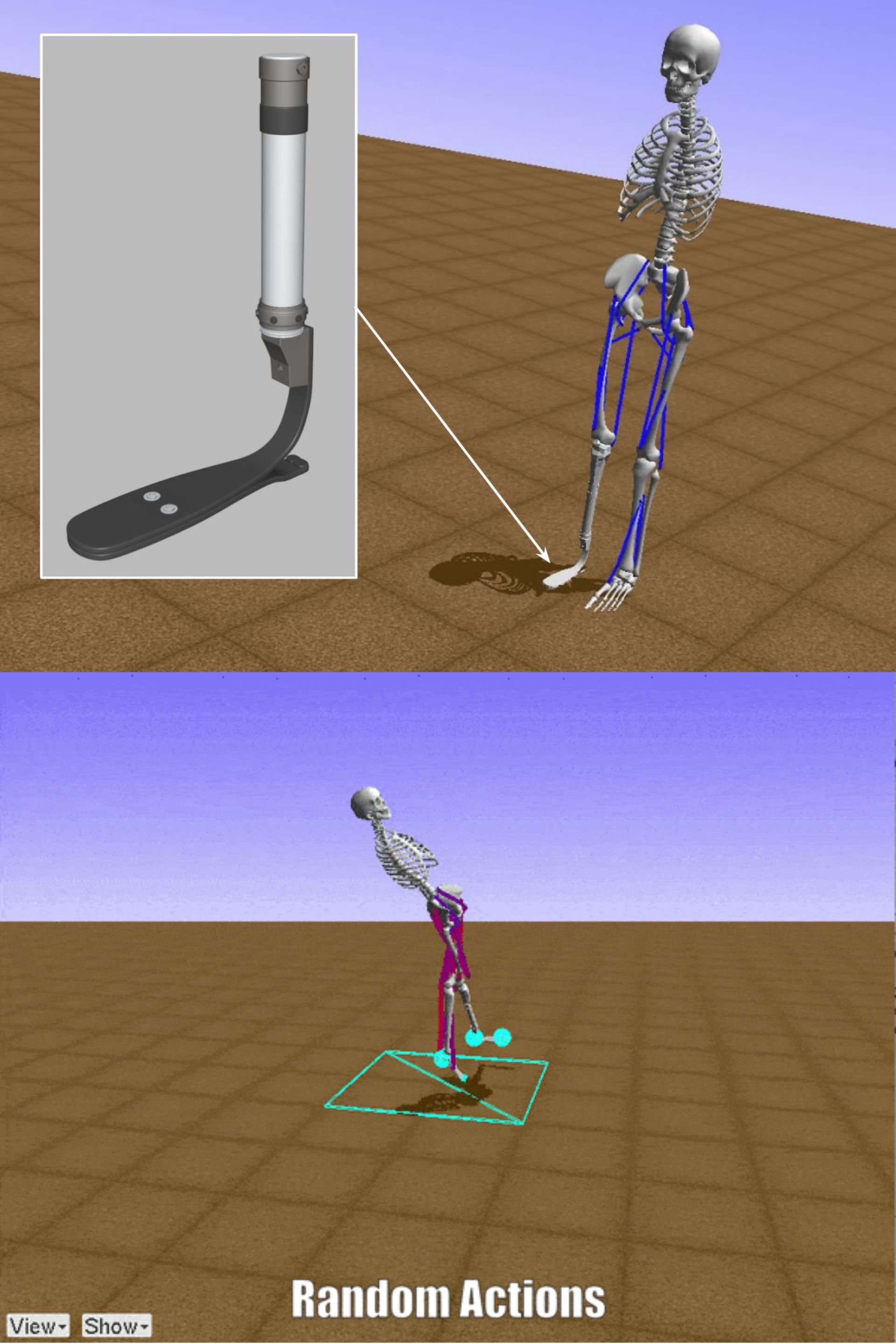
OpenSim models one human leg and prosthetic in another leg.
Observations
the observations can be divided into five components:
-
Body parts: the agent observes its position, velocity, acceleration, rotation, rotational velocity, and rotational acceleration.
-
Joints: the agent observes its position, velocity and acceleration.
-
Muscles: the agent observes its activation, fiber force, fiber length and fiber velocity.
-
Forces: describes the forces acting on body parts.
-
Center of mass: the agent observes the position, velocity, and acceleration.
Actions
-
Muscles activation, lenght and velocity
-
Joints angels.
-
Tendons.
Reward
Where the is the horizontal velocity vector of the pelvi which is function of all state variables.
The termination condition for the episode is filling 300 steps or the height of the pelvis falling below 0.6 meters
Algorithms and Hyperparameters
-
DDPG is a model-free, off-policy actor-critic algorithm using deep function approximators that can learn policies in high-dimensional, continuous action spaces.DDPG is based on the deterministic policy gradient (DPG) algorithm. it combines the actor-critic approach with insights from the recent success of Deep Q Network (DQN).
-
PPO is a policy optimization method that use multiple epochs of stochastic gradient ascent to perform each policy update.
-
TRPO is a model free, on-policy optimization method that effective for optimizing large nonlinear policies such as neural networks.
Results
| TRPO | PPO | DDPG | |
|---|---|---|---|
| Mean Reward | 43 | -58 | -42 |
| Maximum Reward | 194 | 70 | 113 |

Demo
- Random Actions




Discussion
-
OpenSim ProstheticsEnv is a very complex environment, it contains more than 158 continuous state variables and 19 continuous action variables.
-
RL algorithms take a long time to build a complex policy which has the ability to compute all state variables and select action variables which will maximize the reward.
-
DDPG algorithm achieves good reward because it designed for high dimensions continuous space environments and it uses the replay buffer.
-
PPO the least training time comparing to DDPG and TRPO because PPO uses gradient algorithm approximation instance of the conjugate gradient algorithm.
-
TRPO algorithm achieved the maximum Reward because it takes time to reach the “trusted” region so it slower than DDPG and PPO .
Limitations
-
The prosthetic model can not walk for large distances.
-
Each experiment runs for one time, So we are planing to Repeat each experiment number of times with different random seeds and take the average and variance.
-
We used same hyperparameters for all algorithm to make benchmarking between algorithms, we need to select the best hyperparameters for each algorithm and environment.
-
We benchmarcked three RL algorithms only and from one library(ChainerRL). So we are planing to use different implementations.
-
We transfer learning between similar agents.
Installation
ChainerRL libary
-
ChainerRL is a deep reinforcement learning library that implements various state-of-the-art deep reinforcement algorithms in Python using Chainer, a flexible deep learning framework.
-
ChainerRL contains DQN, DDPG, TRPO, PPO, etc Reinforcment Learning algorithms.
Environment
To model physics and biomechanics we use OpenSim - a biomechanical physics environment for musculoskeletal simulations.
Installing
Install OpenSim Envirnment
conda create -n opensim-rl -c kidzik opensim python=3.6.1
source activate opensim-rl
Install ChainerRL libary
pip install chainerrl
References
-
T. Garikayi, D. van den Heever and S. Matope, (2016), Robotic prosthetic challenges for clinical applications, IEEE International Conference on Control and Robotics Engineering (ICCRE), Singapore, 2016, pp. 1-5. doi: 10.1109/ICCRE.2016.7476146
-
Joshi, Girish \& Chowdhary, Girish. (2018). Cross-Domain Transfer in Reinforcement Learning using Target Apprentice.
-
Lillicrap, Timothy \& J. Hunt, Jonathan \& Pritzel, Alexander \& Heess, Nicolas \& Erez, Tom \& Tassa, Yuval \& Silver, David \& Wierstra, Daan. (2015). Continuous control with deep reinforcement learning. CoRR.
-
Attia, Alexandre \& Dayan, Sharone. (2018). Global overview of Imitation Learning.
- Cheng, Qiao \& Wang, Xiangke \& Shen, Lincheng. (2017). An Autonomous Inter-task Mapping Learning Method via Artificial Neural Network for Transfer Learning. 10.1109/ROBIO.2017.8324510.
- J.J. Zhu, DAgger algorithm implementation, (2017), GitHub repository, https://github.com/jj-zhu/jadagger.